
于大二时开始接触图像识别,至今已有两年时间。他也做过很多与图像相关的项目,包括人脸识别、垃圾分类系统、新冠肺炎检测系统等。最近想接触一下语音识别,然后记录第一个语音识别项目。
项目起源
其实这个项目并不是作者完全开发出来的,而是一个同学在做毕业设计的时候给我的。正好适合我研究。
主要代码
主要代码如下:
from pyaudio import PyAudio,paInt16
import time,wave
class mic():
'''录音类'''
def success(self,results):
wf = wave.open("123.wav",'wb')
wf.setnchannels(1) # set channels 1 or 2
wf.setsampwidth(2) # set sampwidth 1 or 2
wf.setframerate(16000) # set framerate 8K or 16K
wf.writeframes(results) # write data
wf.close()
def main(self):
pa = PyAudio()
stream = pa.open(format = paInt16,
#单声道,采样率16000
channels=1,rate=16000,input=True,
frames_per_buffer=512)
frames = []
time_start = time.time()
while 1:
data = stream.read(512,exception_on_overflow = False)
frames.append(data)
if time.time() - time_start>=3.5 :
break
stream.close()
self.success( b''.join(frames) )
if __name__ == '__main__':
mic().main()
项目运行
初始化界面如下:
![图片[1]-接触一下语音识别,再此记录一下第一个语音项目项目-老王博客](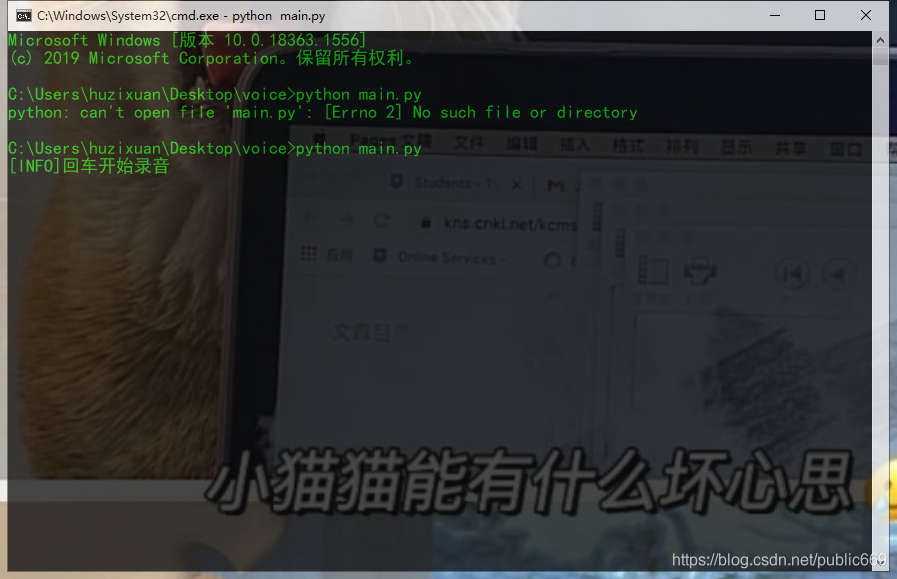)
在初始化界面中,只需要点击回车键即可进行语音识别。录制音频后,稍等片刻,将口语替换为文字
![图片[2]-接触一下语音识别,再此记录一下第一个语音项目项目-老王博客](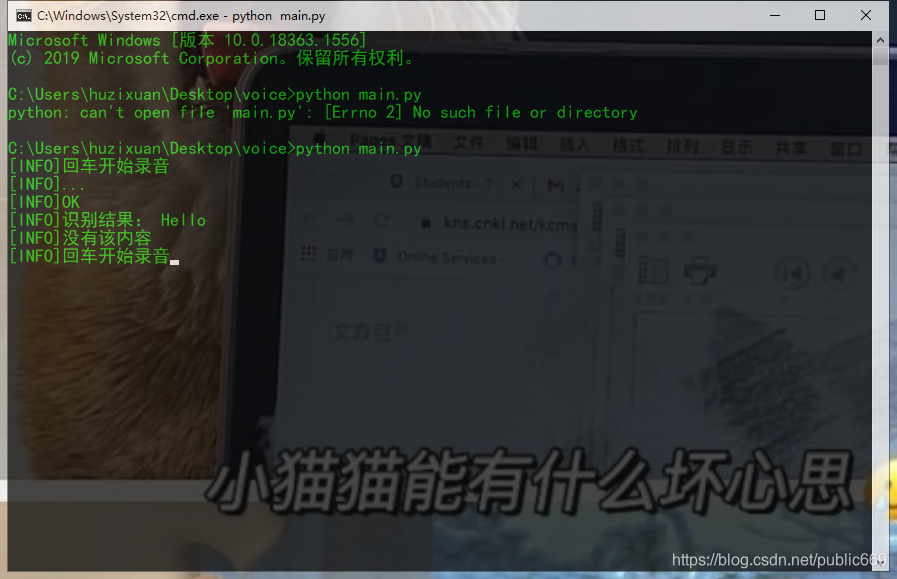)
此外,还可以进行语音操作声音识别算法源代码,比如通过语音命令声音识别算法源代码,这里可以临时播放音乐。
![图片[3]-接触一下语音识别,再此记录一下第一个语音项目项目-老王博客](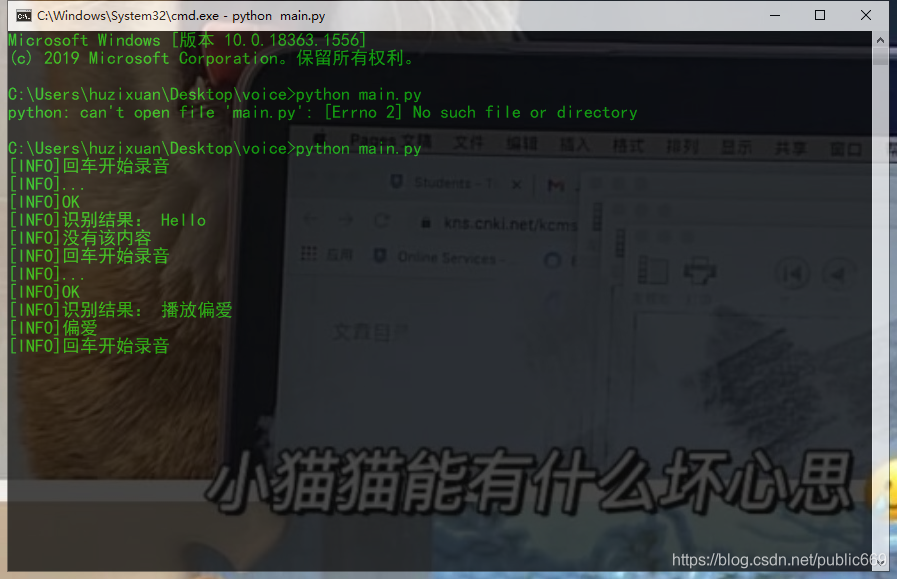)
语音识别可以这么有趣,我觉得以后可以更懒一点。只要动动嘴唇,就可以对电脑进行相应的操作,非常方便。
© 版权声明
THE END
喜欢就支持一下吧








![《金瓶梅》崇祯版等多版本合集(包括名家点评本)[Epub.Mobi.PDF]推荐-老王博客](https://www.9im.cn/wp-content/uploads/2021/05/444444443.jpg)

![表情[xia]-老王博客](https://www.9im.cn/wp-content/themes/zibll5.73/img/smilies/xia.gif)
![表情[zhayanjian]-老王博客](https://www.9im.cn/wp-content/themes/zibll5.73/img/smilies/zhayanjian.gif)
![表情[liulei]-老王博客](https://www.9im.cn/wp-content/themes/zibll5.73/img/smilies/liulei.gif) 我也不是骗子,我以前有QQ号,但是无法登录了,申诉也不给我,真的没办法,有没有人愿意帮这个忙,万分感谢。
我也不是骗子,我以前有QQ号,但是无法登录了,申诉也不给我,真的没办法,有没有人愿意帮这个忙,万分感谢。![表情[fadai]-老王博客](https://www.9im.cn/wp-content/themes/zibll5.73/img/smilies/fadai.gif)





请登录后发表评论
注册
社交帐号登录